
PatchTST:A Time Series is Worth 64 Words Long-term Forecasting with Transformers-论文阅读
Date:
本文介绍了2023年ICLR上的一项工作,提出PatchTST模型,通过改进Transformer架构,包括将时间序列切分为Patch以捕捉局部信息和引入通道独立性,实现了更高效的长期预测,且在性能上超越了线性模型DLinear。
前言
我们在之前的文章已经分析了直接把transformer应用到时间序列预测问题的不足,其中我们总结了4个不足:分别是:
- 注意力机制的计算复杂度高,为 O(n^2),并且计算得出的权重仅有少部分有用;
- 注意力机制仅建立单时间点位之间的关系,实际能提取到的信息非常有限;
- 对时序或者说位置的建模表示不够充分,而时序任务中前后位置关系是重中之重;
- 没有专门的机制在数据“平稳化(之后详解)”和“非平稳化”之间达到合适的平衡;
其中Informer对第一点做了较大的改进;Non-stationary Transformers围绕第四点做了较多改进。那么2023年ICLR的一篇文章,对第一、二、三点,特别是第二点做了极大的改进。Patch TST发表后,现在已经有大量的Patch相关的时序论文发表,如下是一些patch相关的时序论文,Patch俨然成为最新的时序热点趋势。
- 1.香港科技大学:A Multi-Scale Decomposition MLP-Mixer for Time Series Analysis
- 2.华为:Multi-resolution Time-Series Transformer for Long-term Forecasting
文章贡献
- 1、将时间序列按照一定大小的窗口和步长切分成Patch,作为模型输入的Token捕捉局部信息;
- 2、通道独立性:以多变量时间序列为例,每个通道包含一个单变量时间序列,共享相同的嵌入和权重。 (据说是因为前年很火的线性模型DLinear原文中对Transformer类模型进行时间序列预测提出的质疑,该文做出了回答并改进,最后使得基于Transformer的PatchTST模型在长期预测上效果超过线性模型DLinear。)
Patch
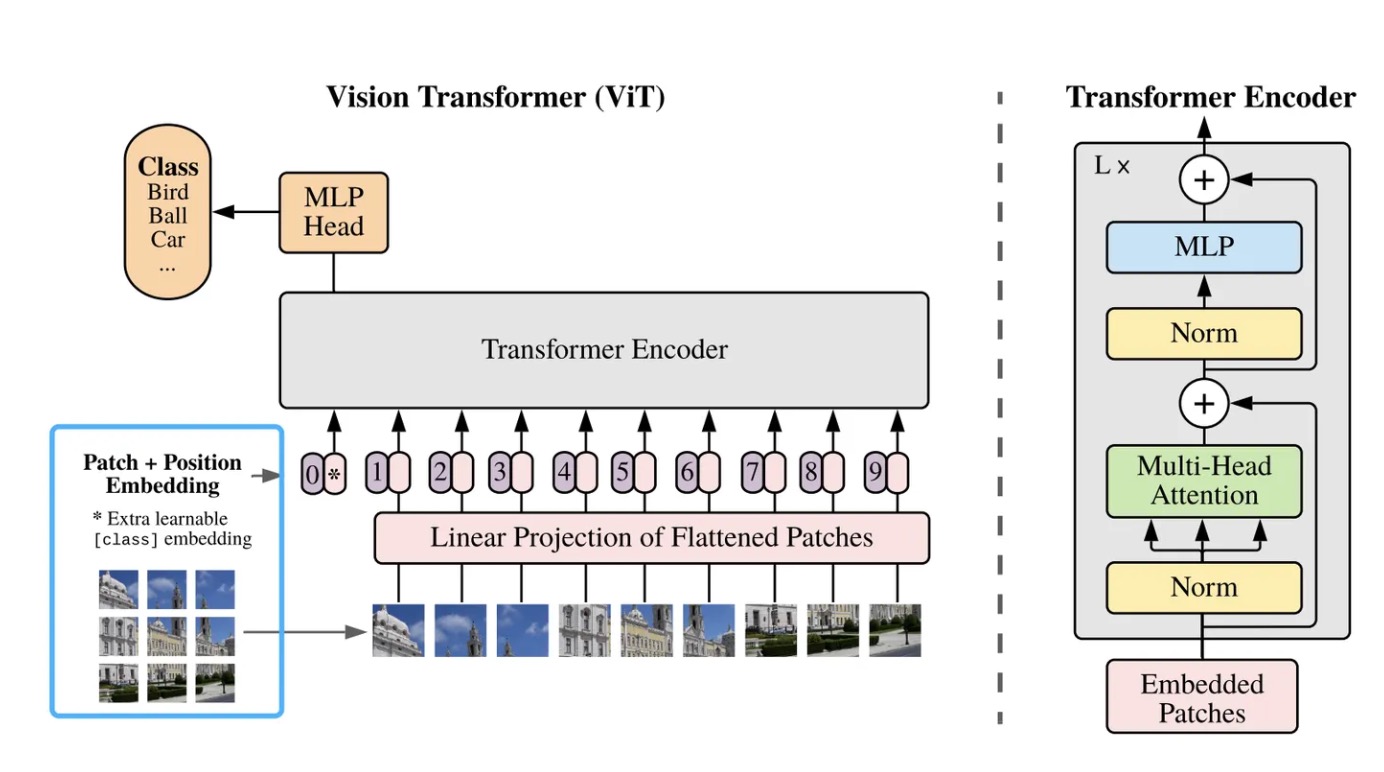
首先Patch,顾名思义,就是将序列进行分块,每一个Patch块相当于模型的输入。 早在CV领域就有Patch的思想了,Vision Transformer模型中的Patch是将输入图像分割成均匀大小的区域,每个图像块作为Transformer输入的Token,用来捕获图像内部和区域的关系。 在时间序列中也类似,照一定大小的窗口和步长切分成Patch,这些Patch可以是重叠的或非重叠的。Patch长度为P,步长为S,通过Patch,输入的数量可以从L减少到大约L/S,而注意力机制的内存使用和计算复杂度是成平方减少的。
- Patch的改进优势:
- 1.降低时间和空间复杂度。Attention的复杂度与输入Token的数量成二次方关系,每一个Patch代表一个Token而不是以往每个时间点代表一个Token,减少了Token数量,从而降低复杂度。
- 2.保持时间序列的局部性。每个Patch捕捉了局部信息,使模型关注了不同区域的特征。相邻时间点的值很接近,而以一个Patch作为计算注意力的最小单位更合理。
- 3.减少Head的参数量。分Patch前Head大小为(LD)×(MT),其中L为输入序列长度,M为序列个数;分Patch后将L减少到Patch的个数N,这样就不需要逐时间点处理,集中在每个Patch上处理,有效减少参数量。
不拘泥于时序数据,我们将patch的好处总结如下:
- 适应Transformer模型: 对于图像任务而言,将图像分割成块状区域允许Transformer模型处理视觉数据。Transformer原本是为处理序列数据设计的,而将图像划分成块后,每个块可以被看作是序列中的一个token,这样Transformer模型可以直接处理图像。
- 区域特征提取: 每个时序/图像块捕捉了局部区域的信息,使模型能够关注不同区域的特征。这有助于模型更好地理解时序/图像的局部信息,特别是单纯建立。
- 减少参数量: 将时序/图像块划分成小块可以减少模型需要处理的维度。这样一来,模型不需要逐个时间点/每一个像素进行处理,而是集中在每个块上进行处理,有效减少了模型的参数量,降低了计算复杂度。
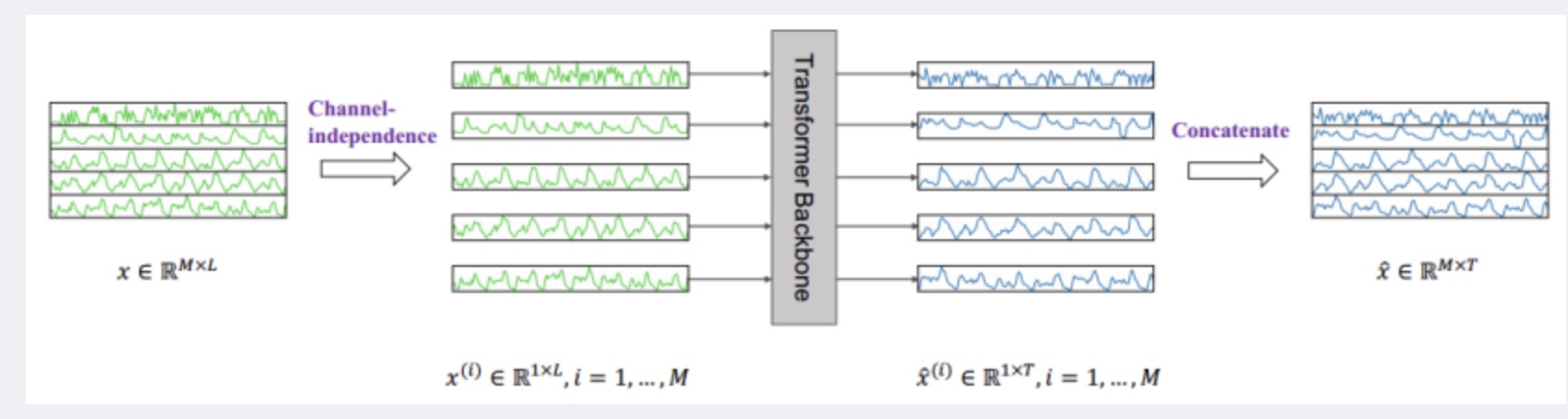
通道独立性
以往基于Transformer的模型采用通道混合的方式,对于多变量时间序列,直接将时间序列所有维度形成的向量投影到嵌入空间来混合多个通道的信息。通道独立性将多元时间序列中的每一维分别输入到Backbone中单独处理,再将预测结果沿维度方向拼接起来,相当于不同维度视为独立的,而嵌入和权重在各维度中是共享的。
- 对于多变量时间序列来说,不同变量(即不同通道)的数据有着不同规律,如果直接混合后投射到同一空间中学习比较困难。
- 一个通道中的数据如果有噪声,很容易影响其他通道。
- 通道独立性不容易过拟合。
PatchTST模型结构图如下:
- 图b每个通道的单变量序列通过实例归一化操作分割为多个Patch,用来作为Transformer的输入Token。
- 图c的自监督学习通过随机赋值0的方式遮盖部分Patch,然后通过自监督重建被遮盖的数据,可以更好捕捉时间序列中的模式和特征。
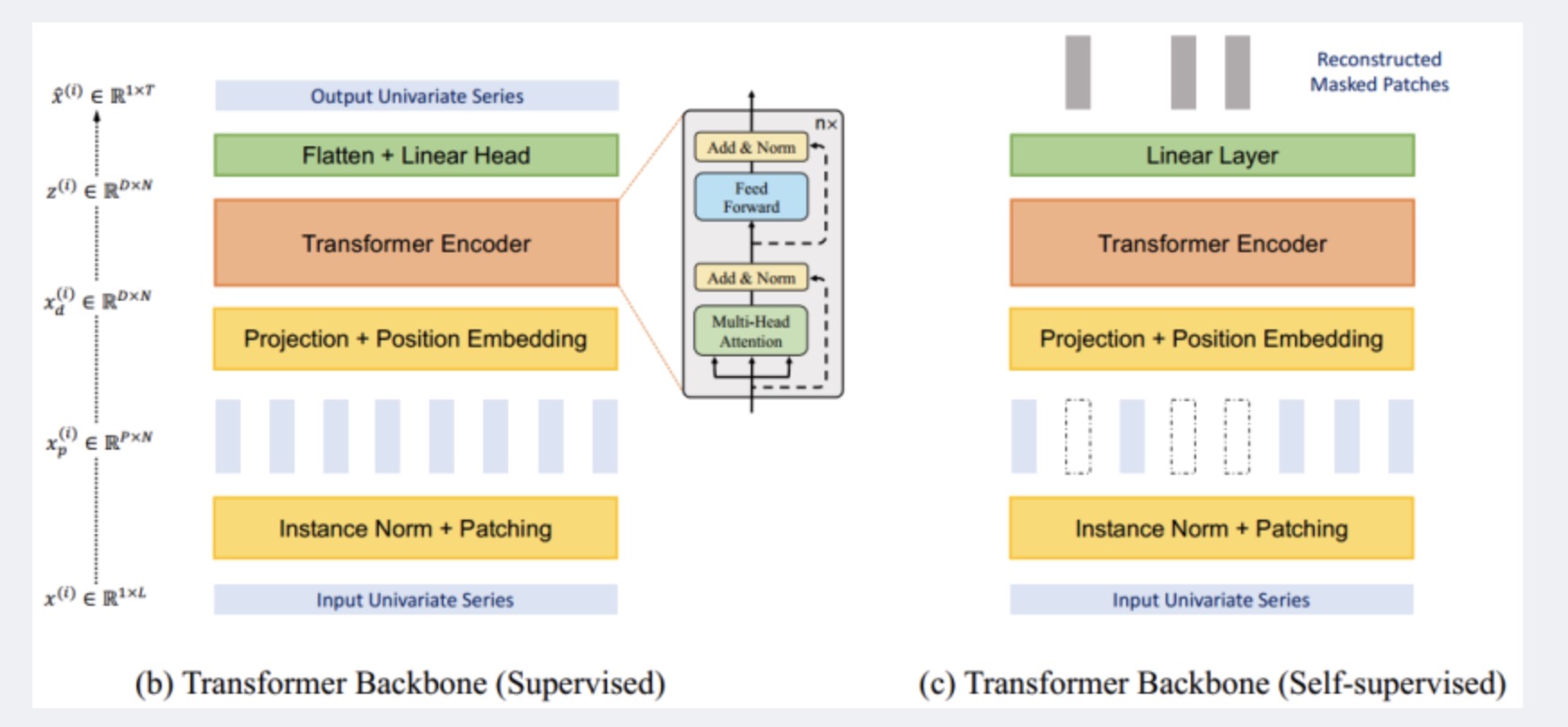
模型对每个输入的单变量时间序列进行分割,形成patch,注意这些patch可以是重叠的或非重叠的。Patch长度为 P,步长为 S(两个连续patch之间的不重叠区域),那么,patch的数量可以表示为N = [(L−P) /s] + 2。通过patch,输入的数量可以从 L 减少到大约 L/S。而注意力机制的内存使用和计算复杂度是成平方减少的。
图(b)和图(c)在结构上的区别在于图(b)最后进行了Flatten,然后进行预测。在训练方法上的主要区别在于,图(c)通过随机赋值为0的方式遮盖了部分patch,然后通过self-supervised重建被遮盖的数据。通过这种自监督学习的方式,模型可以更好地捕捉时间序列中的模式和特征。
自监督学习
自监督表示学习已成为从未标记数据中提取高层抽象表示的热门方法。在PatchTST中,作者也是故意随机移除输入序列的一部分内容,并训练模型恢复缺失的内容。然而,不同于文本,如果我们不进行patch,直接把时序数据输入则会存在两个潜在问题:
- 当前时间步的遮罩值可以通过与紧随前后的时间值进行插值轻易推断,而不需要对整个序列有高层次的理解,这与我们学习整个信号的重要抽象表示的目标不符合。
- 已知我们有L 个时间步的表示向量,D维空间, M 个变量,每个变量具有预测范围 T。则输出需要一个维度为 (L⋅D)×(M⋅T)的参数矩阵 。如果这四个值中的任何一个或所有值都很大,那么这个矩阵可能会特别大。当下游训练样本数量稀缺时,这可能导致过拟合问题。